
70-776 Exam Questions - Online Test
70-776 Premium VCE File

150 Lectures, 20 Hours

We offers 70-776 Dumps. "Perform Big Data Engineering on Microsoft Cloud Services (beta)", also known as 70-776 exam, is a Microsoft Certification. This set of posts, Passing the 70-776 exam with 70-776 Exam Questions and Answers, will help you answer those questions. The 70-776 Free Practice Questions covers all the knowledge points of the real exam. 100% real 70-776 Study Guides and revised by experts!
Online Microsoft 70-776 free dumps demo Below:
NEW QUESTION 1
You are using a Microsoft Azure Stream Analytics query language. You are outputting data from an input click stream.
You need to ensure that when you consecutively receive two rows from the same IP address within one minute, only the first row is outputted.
Which functions should you use in the WHERE statement?
- A. Last and HoppingWindow
- B. Last and SlidingWindow
- C. LAG and HoppingWindow
- D. LAG and Duration
Answer: B
NEW QUESTION 2
You have a Microsoft Azure Data Lake Analytics service.
You need to write a U-SQL query to extract from a CSV file all the users who live in Boston, and then to save the results in a new CSV file.
Which U-SQL script should you use?



- A. Option A
- B. Option B
- C. Option C
- D. Option D
Answer: A
NEW QUESTION 3
You manage an on-premises data warehouse that uses Microsoft SQL Server. The data warehouse contains 100 TB of data. The data is partitioned by month. One TB of data is added to the data warehouse each month.
You create a Microsoft Azure SQL data warehouse and copy the on-premises data to the data warehouse.
You need to implement a process to replicate the on-premises data warehouse to the Azure SQL data warehouse. The solution must support daily incremental updates and must provide error handling. What should you use?
- A. the Azure Import/Export service
- B. SQL Server log shipping
- C. Azure Data Factory
- D. the AzCopy utility
Answer: C
NEW QUESTION 4
You have a Microsoft Azure Data Factory that recently ran several activities in parallel. You receive alerts indicating that there are insufficient resources.
From the Activity Windows list in the Monitoring and Management app, you discover the statuses described in the following table.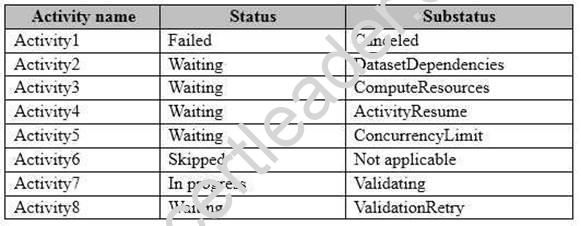
Which activity cannot complete because of insufficient resources?
- A. Activity2
- B. Activity4
- C. Activity5
- D. Activity7
Answer: C
NEW QUESTION 5
You have a fact table named PowerUsage that has 10 billion rows. PowerUsage contains data about customer power usage during the last 12 months. The usage data is collected every minute. PowerUsage contains the columns configured as shown in the following table.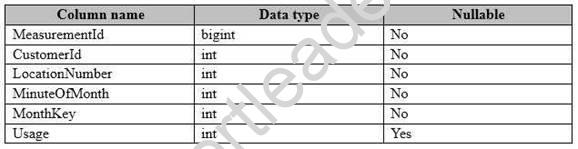
LocationNumber has a default value of 1. The MinuteOfMonth column contains the relative minute within each month. The value resets at the beginning of each month.
A sample of the fact table data is shown in the following table.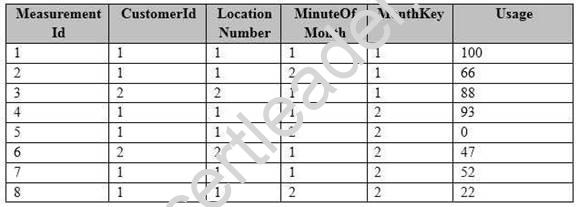
There is a related table named Customer that joins to the PowerUsage table on the CustomerId column. Sixty percent of the rows in PowerUsage are associated to less than 10 percent of the rows in Customer. Most queries do not require the use of the Customer table. Many queries select on a specific month.
You need to minimize how long it takes to find the records for a specific month. What should you do?
- A. Implement partitioning by using the MonthKey colum
- B. Implement hash distribution by using the CustomerId column.
- C. Implement partitioning by using the CustomerId colum
- D. Implement hash distribution by using the MonthKey column.
- E. Implement partitioning by using the MonthKey colum
- F. Implement hash distribution by using the MeasurementId column.
- G. Implement partitioning by using the MinuteOfMonth colum
- H. Implement hash distribution by using the MeasurementId column.
Answer: C
NEW QUESTION 6
Note: This question is part of a series of questions that present the same scenario. Each question in
the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a table named Table1 that contains 3 billion rows. Table1 contains data from the last 36 months.
At the end of every month, the oldest month of data is removed based on a column named DateTime.
You need to minimize how long it takes to remove the oldest month of data. Solution: You implement a columnstore index on the DateTime column. Does this meet the goal?
- A. Yes
- B. No
Answer: A
NEW QUESTION 7
DRAG DROP
You need to copy data from Microsoft Azure SQL Database to Azure Data Lake Store by using Azure Data Factory.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.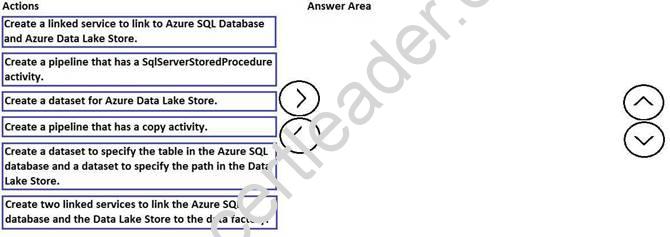
Answer:
Explanation:
References:
https://docs.microsoft.com/en-us/azure/data-factory/copy-activity-overview
NEW QUESTION 8
DRAG DROP
Note: This question is part of a series of questions that present the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
Start of repeated scenario
You are migrating an existing on-premises data warehouse named LocalDW to Microsoft Azure. You will use an Azure SQL data warehouse named AzureDW for data storage and an Azure Data Factory named AzureDF for extract, transformation, and load (ETL) functions.
For each table in LocalDW, you create a table in AzureDW.
On the on-premises network, you have a Data Management Gateway.
Some source data is stored in Azure Blob storage. Some source data is stored on an on-premises Microsoft SQL Server instance. The instance has a table named Table1.
After data is processed by using AzureDF, the data must be archived and accessible forever. The archived data must meet a Service Level Agreement (SLA) for availability of 99 percent. If an Azure region fails, the archived data must be available for reading always. The storage solution for the archived data must minimize costs.
End of repeated scenario.
Which three actions should you perform in sequence to migrate the on-premises data warehouse to Azure SQL Data Warehouse? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Answer:
Explanation:
References:
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-load-from-sql-server-with-polybase
NEW QUESTION 9
Note: This question is part of a series of questions that present the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
Start of repeated scenario
You are migrating an existing on-premises data warehouse named LocalDW to Microsoft Azure. You will use an Azure SQL data warehouse named AzureDW for data storage and an Azure Data Factory named AzureDF for extract, transformation, and load (ETL) functions.
For each table in LocalDW, you create a table in AzureDW.
On the on-premises network, you have a Data Management Gateway.
Some source data is stored in Azure Blob storage. Some source data is stored on an on-premises Microsoft SQL Server instance. The instance has a table named Table1.
After data is processed by using AzureDF, the data must be archived and accessible forever. The archived data must meet a Service Level Agreement (SLA) for availability of 99 percent. If an Azure region fails, the archived data must be available for reading always. The storage solution for the archived data must minimize costs.
End of repeated scenario.
You need to define the schema of Table1 in AzureDF. What should you create?
- A. a gateway
- B. a linked service
- C. a dataset
- D. a pipeline
Answer: C
NEW QUESTION 10
Note: This question is part of a series of questions that present the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
Start of repeated scenario
You are migrating an existing on-premises data warehouse named LocalDW to Microsoft Azure. You will use an Azure SQL data warehouse named AzureDW for data storage and an Azure Data Factory named AzureDF for extract, transformation, and load (ETL) functions.
For each table in LocalDW, you create a table in AzureDW.
On the on-premises network, you have a Data Management Gateway.
Some source data is stored in Azure Blob storage. Some source data is stored on an on-premises Microsoft SQL Server instance. The instance has a table named Table1.
After data is processed by using AzureDF, the data must be archived and accessible forever. The archived data must meet a Service Level Agreement (SLA) for availability of 99 percent. If an Azure region fails, the archived data must be available for reading always. End of repeated scenario.
You need to connect AzureDF to the storage account. What should you create?
- A. a gateway
- B. a dataset
- C. a linked service
- D. a pipeline
Answer: C
Explanation:
References:
https://docs.microsoft.com/en-us/azure/data-factory/v1/data-factory-azure-blob-connector
NEW QUESTION 11
You have a Microsoft Azure Data Lake Analytics service.
You have a CSV file that contains employee salaries.
You need to write a U-SQL query to load the file and to extract all the employees who earn salaries that are greater than $100,000. You must encapsulate the data for reuse.
What should you use?
- A. a table-valued function
- B. a view
- C. the extract command
- D. the output command
Answer: A
Explanation:
References:
https://docs.microsoft.com/en-au/azure/data-lake-analytics/data-lake-analytics-u-sql-catalog
NEW QUESTION 12
Note: This question is part of a series of questions that present the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
Start of repeated scenario
You are migrating an existing on-premises data warehouse named LocalDW to Microsoft Azure. You will use an Azure SQL data warehouse named AzureDW for data storage and an Azure Data Factory named AzureDF for extract, transformation, and load (ETL) functions.
For each table in LocalDW, you create a table in AzureDW.
On the on-premises network, you have a Data Management Gateway.
Some source data is stored in Azure Blob storage. Some source data is stored on an on-premises Microsoft SQL Server instance. The instance has a table named Table1.
After data is processed by using AzureDF, the data must be archived and accessible forever. The archived data must meet a Service Level Agreement (SLA) for availability of 99 percent. If an Azure region fails, the archived data must be available for reading always.
End of repeated scenario.
You need to configure Azure Data Factory to connect to the on-premises SQL Server instance. What should you do first?
- A. Deploy an Azure virtual network gateway.
- B. Create a dataset in Azure Data Factory.
- C. From Azure Data Factory, define a data gateway.
- D. Deploy an Azure local network gateway.
Answer: C
Explanation:
References:
https://docs.microsoft.com/en-us/azure/data-factory/v1/data-factory-move-data-between-onprem- and-cloud
NEW QUESTION 13
HOTSPOT
You are creating a series of activities for a Microsoft Azure Data Factory. The first activity will copy an input dataset named Dataset1 to an output dataset named Dataset2. The second activity will copy a dataset named Dataset3 to an output dataset named Dataset4.
Dataset1 is located in Azure Table Storage. Dataset2 is located in Azure Blob storage. Dataset3 is located in an Azure Data Lake store. Dataset4 is located in an Azure SQL data warehouse.
You need to configure the inputs for the second activity. The solution must ensure that Dataset3 is copied after Dataset2 is created.
How should you complete the JSON code for the second activity? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
References:
https://github.com/aelij/azure-content/blob/master/articles/data-factory/data-factory-create- pipelines.md
NEW QUESTION 14
Note: This question is part of a series of questions that present the same scenario. Each question in
the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are monitoring user queries to a Microsoft Azure SQL data warehouse that has six compute nodes.
You discover that compute node utilization is uneven. The rows_processed column from sys.dm_pdw_workers shows a significant variation in the number of rows being moved among the distributions for the same table for the same query.
You need to ensure that the load is distributed evenly across the compute nodes. Solution: You add a nonclustered columnstore index.
Does this meet the goal?
- A. Yes
- B. No
Answer: B
NEW QUESTION 15
You plan to use Microsoft Azure Event Hubs to ingest sensor data. You plan to use Azure Stream Analytics to analyze the data in real time and to send the output directly to Azure Data Lake Store.
You need to write events to the Data Lake Store in batches. What should you use?
- A. Apache Storm in Azure HDInsight
- B. Stream Analytics
- C. Microsoft SQL Server Integration Services (SSIS)
- D. the Azure CLI
Answer: B
Explanation:
References:
https://docs.microsoft.com/en-us/azure/data-lake-store/data-lake-store-data-scenarios
NEW QUESTION 16
DRAG DROP
You are designing a Microsoft Azure analytics solution. The solution requires that data be copied from Azure Blob storage to Azure Data Lake Store.
The data will be copied on a recurring schedule. Occasionally, the data will be copied manually. You need to recommend a solution to copy the data.
Which tools should you include in the recommendation? To answer, drag the appropriate tools to the correct requirements. Each tool may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Answer:
Explanation: 
Thanks for reading the newest 70-776 exam dumps! We recommend you to try the PREMIUM 2passeasy 70-776 dumps in VCE and PDF here: https://www.2passeasy.com/dumps/70-776/ (91 Q&As Dumps)
- [2021-New] Microsoft 70-354 Dumps With Update Exam Questions (11-20)
- [2021-New] Microsoft 70-410 Dumps With Update Exam Questions (11-20)
- Microsoft AZ-100 Exam Questions 2021
- How Many Questions Of AZ-700 Test Engine
- [2021-New] Microsoft 70-411 Dumps With Update Exam Questions (21-30)
- Microsoft 70-537 Braindumps 2021
- [2021-New] Microsoft 70-534 Dumps With Update Exam Questions (31-40)
- [2021-New] Microsoft 70-483 Dumps With Update Exam Questions (101-110)
- Microsoft AZ-102 Study Guides 2021
- [2021-New] Microsoft 70-411 Dumps With Update Exam Questions (131-140)